
Sistema de archivos de Docker
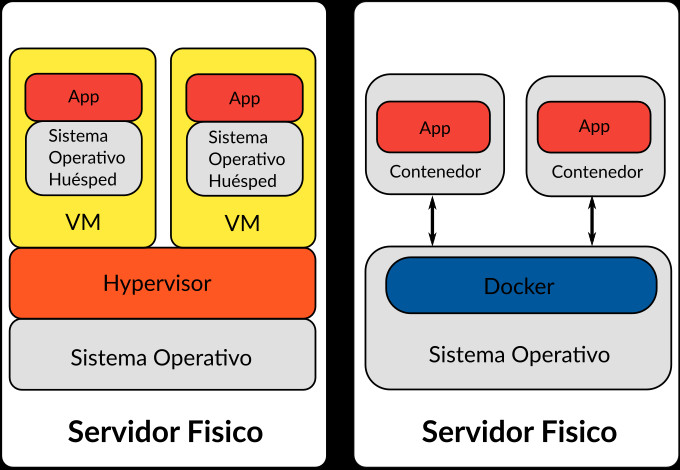 En la Práctica básica con Docker vimos los elementos básicos de Docker, así que ahora vamos a hablar sobre como se almacenan esos elementos: los controladores de almacenamiento y el sistema de archivos de Docker. Vamos a ver dónde y cómo Docker almacena datos y cómo administra los sistemas de archivos de los contenedores.
En la Práctica básica con Docker vimos los elementos básicos de Docker, así que ahora vamos a hablar sobre como se almacenan esos elementos: los controladores de almacenamiento y el sistema de archivos de Docker. Vamos a ver dónde y cómo Docker almacena datos y cómo administra los sistemas de archivos de los contenedores.
Comencemos con cómo Docker almacena datos en el sistema de archivos local. Cuando se instala Docker en un sistema, crea una estructura de carpetas en var/lib/docker que tiene varias carpetas debajo: aufs, containers, image, volumes, etc.
Aquí es donde Docker almacena todos sus datos de manera predeterminada. Cuando digo datos, me refiero a archivos relacionados con imágenes y contenedores que se ejecutan en el host de Docker. Por ejemplo, todos los archivos relacionados con contenedores se almacenan en la carpeta de contenedores y los archivos relacionados con imágenes se almacenan en la carpeta de imágenes. Y todos los volúmenes creados por los contenedores Docker se crean en la carpeta de volúmenes.
Almacenamiento de las capas
En Creación de imágenes para Docker hemos visto que cuando Docker construye imágenes, las construye en una arquitectura en capas. Cada línea de instrucciones en el archivo Docker crea una nueva capa en la imagen Docker con solo los cambios de la capa anterior. Por ejemplo, para esta composición:
FROM ubuntu
RUN apt-get update && apt-get -y install python
RUN pip install flask flask-mysql
COPY . /opt/source-code
ENTRYPOINT FLASK_APP=/opt/source-code/app.py flask run
La primera capa es un sistema operativo Ubuntu base seguido de la segunda instrucción que crea una segunda capa que instala todos los paquetes APT. Y luego, la tercera instrucción crea una tercera capa que con los paquetes de Python seguida de la cuarta capa que copia el código fuente. Y finalmente, la quinta capa que actualiza el punto de entrada de la imagen.
Ya que cada capa solo almacena los cambios de la capa anterior, también se refleja en el tamaño. Si miras en el sistema de archivos de Docker, la base de la imagen, tiene alrededor de 120 megabytes de tamaño. Los paquetes apt que se instalan son de alrededor de 300 MB y luego las capas restantes son más pequeñas.
Veamos una segunda aplicación:
FROM ubuntu
RUN apt-get update && apt-get -y install python
RUN pip install flask flask-mysql
COPY app2.py /opt/source-code
ENTRYPOINT FLASK_APP=/opt/source-code/app2.py flask run
Esta aplicación tiene un archivo acoplable diferente pero es muy similar a nuestra primera aplicación ya que usa la misma imagen base que un ubuntu y usa las mismas dependencias de python y flask, pero usa un código fuente diferente para crear una aplicación diferente y también un punto de entrada diferente. Cuando ejecuto el comando docker build para crear una nueva imagen para esta aplicación, cómo las tres primeras capas de ambas aplicaciones son las mismas, Docker no va a construir las tres primeras capas. Reutiliza las mismas tres capas que creó para la primera aplicación del caché y solo crea las dos últimas capas con las nuevas fuentes y el nuevo punto de entrada. De esta manera Docker construye imágenes más rápido y ahorra espacio en disco.
Esto también es aplicable si actualiza su código de aplicación. Cada vez que actualiza su código de aplicación, Docker reutiliza todas las capas anteriores de la memoria caché y reconstruye rápidamente la imagen de la aplicación actualizando el último código fuente, lo que nos ahorra mucho tiempo durante las reconstrucciones y actualizaciones.
Capas en una aplicación propia
Si leemos las capas de abajo hacia arriba podemos entenderlo mejor. En la base tendremos la capa de ubuntu, encima los paquetes, luego las dependencias y luego el código fuente de la aplicación y por último el punto de entrada. Todas estas capas se crean cuando ejecutamos el comando “docker build” para formar la imagen final de Docker. Una vez que se completa la compilación, no se puede modificar el contenido de estas capas, por lo que son de solo lectura y solo puede modificarlas iniciando una nueva compilación.
Cuando se ejecuta un contenedor basado en la imagen creada (usando el comando “docker run”), Docker crea un contenedor basado en estas capas y crea una nueva capa en la parte superior. En esta capa sí es capaz de escribir y se utiliza para almacenar datos creados por el contenedor, como los archivos de registro de las aplicaciones o cualquier archivo temporal generado por el contenedor o simplemente cualquier archivo modificado por el usuario en ese contenedor. La vida de esta capa es solo mientras el contenedor esté vivo. Cuando el contenedor se destruye esta capa y todos los cambios almacenados en él también se destruyen. Recuerde que todos los contenedores creados con esta imagen comparten la misma capa de imagen.
Si tuviera que iniciar sesión en el contenedor recién creado y decide crear un nuevo archivo llamado temp.txt, crearía ese archivo en la capa contenedor que es de lectura y escritura. Acabamos de decir que los archivos en la capa de imagen son de solo lectura, lo que significa que no puede editar nada en esas capas.
Ejemplo
Tomemos un ejemplo de nuestro código de aplicación. Ya que compilamos nuestro código Python en la imagen, el código es parte de la capa de imagen y, como tal, es de solo lectura. Esto no significa que no pueda modificar el código dentro del contenedor creado. Antes de crear la capa del contenedor, Docker crea automáticamente una copia del archivo en la capa de lectura y escritura, por lo que es posible modificar el archivo en la capa de lectura y escritura. Todas las modificaciones futuras se realizarán en esta copia del archivo en la capa de lectura y escritura. Esto se llama mecanismo de copia en escritura. Esto significa que los archivos en estas capas no se modificarán en la imagen, por lo que la imagen permanecerá igual todo el tiempo hasta que reconstruya la imagen usando el comando de construcción de docker.
Lo que sucede cuando nos deshacemos del contenedor, es que todos los datos almacenados en la capa del contenedor también se eliminan. El cambio que hicimos en la aplicación Python y el nuevo archivo temporal que creamos también se eliminarán.
Montaje de volumen del sistema de archivos de Docker
Si estuviéramos trabajando con una base de datos y quisiéramos preservar los datos creados por el contenedor, podríamos agregar un volumen persistente al contenedor. Para hacer esto primero crear un volumen usando el comando “docker volume create <nombre>”. Entonces, si ejecutamos el comando “docker volume create data_volume”, se crea una carpeta llamada “data_volume” en el directorio “var/lib/docker/volumes”. Luego, cuando ejecuto el contenedor Docker usando el comando “docker run”, podría montar este volumen dentro de la capa de lectura y escritura de los contenedores usando la opción -v: “docker run -v data_volume:/var/lib/mysql mysql”
Con esto, Docker creará un nuevo contenedor y montará el volumen de datos que creamos, en la carpeta var/lib/mysql dentro del contenedor para que todos los datos escritos por la base de datos se almacenen en el volumen creado en el host Docker. Incluso si el contenedor se destruye, los datos siguen activos. Si no se ejecuta el comando “docker volume create” para crear el volumen antes del comando “docker run”, por ejemplo, “docker run -v data_volume2:/var/lib/mysql mysql”, Docker creará automáticamente un volumen denominado data_volume2 y lo montará en el contenedor. Esto se llama montaje de volumen.
Montaje de unión del sistema de archivos de Docker
Si ya tuviéramos nuestros datos en otra ubicación, por ejemplo, en un almacenamiento externo del host Docker llamado /data y nos gustaría almacenar datos de la base de datos en ese volumen y no en la carpeta predeterminada. En ese caso, ejecutaríamos un contenedor con el comando “docker run -v”. Pero en este caso proporcionaremos la ruta completa a la carpeta que nos gustaría montar. Es decir /data/mysql, por lo que creará un contenedor y montará la carpeta en el contenedor. Esto se llama montaje de unión.
Por lo tanto, hay dos tipos de montajes para el sistema de archivos de Docker: un montaje de volumen y un montaje de volumen. El montaje de volumen monta un volumen del directorio de volúmenes y el montaje de unión monta un directorio desde cualquier ubicación en el host Docker. Un último punto a tener en cuenta es que -v es un estilo antiguo. La nueva forma es usar la opción de montaje –mount. Esta es la forma preferida, ya que es más detallado. Por lo tanto, debe especificar cada parámetro en un formato de clave igual a valor: “docker run –mount type=bind,source=/data/mysql,target=/var/lib/mysql mysql”
Controladores
Quien es el responsable de realizar esta operaciones: Mantener la arquitectura en capas, crear una capa de escritura, mover archivos a través de capas, copiar y escribir, etc. Son los controladores de almacenamiento. Dockery utiliza controladores de almacenamiento para habilitar la arquitectura en capas. Algunos de los controladores de almacenamiento comunes son AUFS, ZFS, BTRFS, Device mapper, Overlay, Overlay2… Depende del sistema operativo subyacente que se utilice, por ejemplo, con Ubuntu el controlador de almacenamiento predeterminado es un AUFS, mientras que ese tipo de controlador no está disponible en otros sistemas operativos como fedora o centOS. En esos casos, el Device Mapper puede ser una mejor opción. Docker elegirá el mejor controlador disponible en función del sistema operativo.
Más información en la página de Docker https://docs.docker.com/storage/


