
Motor de Docker
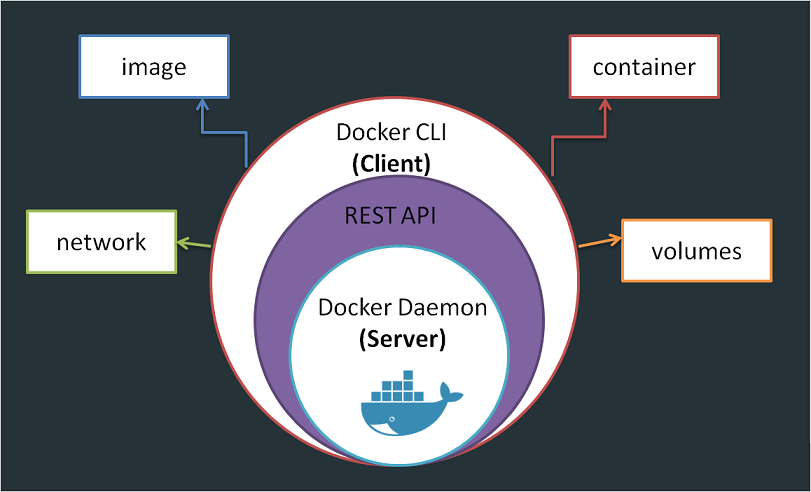
En este artículo, veremos más de cerca la arquitectura de Docker, cómo ejecuta aplicaciones en contenedores aislados y cómo funciona internamente cuando hicimos la Práctica con el comando run de Docker. Cuando hablamos del motor Docker, simplemente nos referimos a un host con Docker instalado en él. Cuando se instala Docker en un host de Linux, en realidad está instalando tres competencias diferentes.
El demonio Docker: Es un proceso en segundo plano que gestiona los objetos Docker, como los volúmenes y las redes de los contenedores de imágenes.
El servidor REST API: Es la interfaz API que los programas pueden usar para hablar con el demonio y proporcionar instrucciones. Se puede crear nuestras propias herramientas utilizando esta API de REST.
La CLI de docker: Es la interfaz en línea de comandos que hemos estado utilizando hasta ahora para realizar acciones como ejecutar un contenedor, detener contenedores que destruyen imágenes, etc. Utiliza la API de REST para interactuar con el demonio de Docker.
Algo que hay que tener en cuenta aquí es que la CLI de Dockers no necesita estar necesariamente en el mismo host. Podría estar en otro sistema como una computadora portátil y aún puede funcionar con un motor Docker remoto. Solo hay que usar la opción -H en el comando docker y especificar la dirección remota del motor Docker y el puerto (“docker -H=remote-docker-engine:2375 <comandos>”)
Estructura
Docker usa el espacio de nombres para aislar los espacios de trabajo, procesos, comunicaciones, sistemas de tiempo de Unix… cada uno crea en su propio espacio de nombres, proporcionando así aislamiento entre los contenedores.
Cada vez que se inicia un sistema Linux, comienza con un proceso con el ID 1. Este es el proceso raíz y comienza todos los demás procesos en el sistema. Cuando el sistema se detiene por completo, tenemos un puñado de procesos que están ejecutándose. Esto se puede ver ejecutando el comando “ps” para enumerar todos los procesos en ejecución. Los IDs de procesos son únicos y dos procesos no pueden tener el mismo proceso ID.
Si creamos un contenedor, que es básicamente un sistema secundario dentro del sistema actual, el sistema secundario debe pensar que es un sistema independiente y que tiene su propio conjunto de procesos empezando con un ID 1, pero sabemos que no existe un aislamiento sólido entre los contenedores y el host subyacente. Así, los procesos que se ejecutan dentro del contenedor son, de hecho, procesos que se ejecutan en el host subyacente. Y sabemos que dos procesos no pueden tener el mismo ID de proceso.
Aquí es donde entra en juego el espacio de nombres. Cada proceso puede tener múltiples id de proceso asociadas. Por ejemplo, cuando los procesos comienzan en el contenedor, en realidad es solo otro conjunto de procesos en el sistema Linux base y obtiene el siguiente ID de proceso disponible. Sin embargo, también obtienen otro ID de proceso comenzando con 1 en el espacio de nombres del contenedor, que solo es visible dentro del contenedor, por lo que el contenedor tiene su propio árbol de proceso raíz y, por lo tanto, es un sistema independiente.
Relación con un sistema real
Digamos que ejecutamos un contenedor nginx. Sabemos que nginx y su contenedor ejecutan un servicio nginx. Si enumeramos todos los servicios dentro del contenedor docker con un comando como “docker exec <ID> ps -eaf”, veríamos que el servicio nginx se ejecuta con una ID de proceso de 1. Este es el proceso del servicio dentro del espacio de nombres del contenedor. Si enumeramos los servicios en el host de Docker con una orden “ps -eaf”, veremos el mismo servicio pero con una ID de proceso diferente que indica que todos los procesos se están ejecutando en el mismo host pero separados en sus propios contenedores usando el espacio de nombres.
Por lo que vemos, el Docker subyacente y los contenedores comparten los mismos recursos del sistema, como la CPU y la memoria. La cantidad de recursos dedicados al host y a los contenedores y cómo Docker administra y comparte los recursos entre los contenedores de manera predeterminada es sin restricciones. Por lo tanto, un contenedor puede terminar utilizando todos los recursos en el host subyacente.
Pero hay una manera de restringir la cantidad de CPU o memoria que un contenedor puede usar. Docker usa tres grupos o grupos de control para restringir la cantidad de recursos de hardware asignados a cada contenedor. Esto se puede hacer proporcionando la opción –cpus en el comando “run”. Un valor de punto cinco asegurará que el contenedor no ocupe más del 50 por ciento de la CPU en cualquier momento dado. Lo mismo ocurre con la memoria. Establecer un valor de 100 megabytes para la opción –memory limita la cantidad de memoria que el contenedor puede usar a 100 megabytes.
“docker run –cpus=.5 –memory=100m ubuntu”
Puedes ver más información en la página https://docs.docker.com/config/containers/resource_constraints/


