
Replicación en Kubernetes
En este artículo se explica la replicación en Kubernetes y su controlador. Los controladores son los cerebros detrás de Kubernetes. Son los procesos que monitorizan el estado de los objetos y responden en consecuencia. Vamos a ver un controlador en particular, el de replicación. Lo primero es conocer qué es una réplica y por qué necesitamos un controlador de replicación.
Casos de uso
Supongamos que tenemos un solo POD ejecutando una aplicación. Si falla, los usuarios ya no podrán acceder. Para evitar que los usuarios pierdan el acceso a la aplicación es mejor tener más de una instancia funcionando al mismo tiempo. De esa forma, si uno falla, todavía tenemos la aplicación ejecutándose en la otra. El controlador de replicación ayuda a ejecutar varias instancias en el clúster, proporcionando una alta disponibilidad. Esto no significa que no se pueda usar un controlador de replicación si solo hay un POD. Incluso con un solo POD, el controlador de replicación puede ayudar a abrir automáticamente un nuevo POD cuando el existente falla. El controlador de replicación asegura que el número especificado se esté ejecutando en todo momento, incluso si es solo uno.
Otra razón por las que se necesita un controlador de replicación es crear múltiples rutas para compartir la carga entre ellas. Si tenemos un solo POD que sirve a un conjunto de usuarios, y aumentamos los PODs, pero nos quedáramos sin recursos, podríamos desplegar PODs adicionales en los otros nodos del clúster. Así que el controlador de replicación abarca varios nodos en el clúster. Nos ayuda a equilibrar la carga a través de múltiples rutas en diferentes nodos, así como a escalar nuestra aplicación.
Hay dos términos similares: controlador de replicación y conjunto de replicas (Replica set). Ambos tienen el mismo propósito pero no es lo mismo. El controlador de replicación es la tecnología más antigua y está siendo reemplazada por el conjunto de réplicas que es la nueva forma recomendada de configurar la replicación. Sin embargo, todo lo que veremos en este artículo es aplicable a ambas tecnologías. Hay diferencias menores en la forma en que funciona cada uno, pero lo veremos más adelante.
Creación de un controlador de replicación.
Se comienza creando un archivo de definición de controlador de replicación como cualquier archivo de definición de Kubernetes (ver YAML orientado a Kubernetes). Para «apiVersion» usaremos «v1» y para «kind» utilizamos «ReplicationControler». Para el apartado de «metadata» necesitaremos datos parecidos a los PODs, que son un «name» con un nombre propio y las «labels» que se quiera, por ejemplo «app» y «type». La siguiente es la parte más crucial del archivo de definición y es la especificación escrita como «spec».
La sección de especificaciones define lo que hay dentro del objeto que estamos creando. En este caso, el controlador de replicación crea varias instancias de un POD. Así que hay que especificar el POD que debe replicar en una sección llamada «template». En esta sección se define el POD que debe crear cada vez que lo necesite. La estructura de la definición es la misma que se usaba en los apartados «metadata» y «spec» en la definición de los POD. Hemos anidado los archivos de definición juntos, el controlador de replicación es el padre y la definición de POD es el hijo.
Para indicar cuántas réplicas necesitamos en el controlador de replicación hay que agregar otra propiedad a la especificación llamada «replicas» y colocando la cantidad de réplicas que necesita debajo.
apiVersion: v1
kind: ReplicationController
metadata:
name: myapp-rc
labels:
app: myapp
type: front-end
spec:
template:
metadata:
name: myapp-pod
labels:
app: myapp
type: front-end
spec:
containers:
- name: nginx-container
image: nginx
replicas: 3
Ejecución de la replicación en Kubernetes
Una vez que el archivo está listo, se ejecuta el comando de creación «kubectl create -f rc-definition.yml». Cuando se crea el controlador de replicación, primero crea la parte utilizando la plantilla de definición de PODs tantas como sea necesario (en nuestro ejemplo, 3). Se puede ver la lista de controladores de replicación creados, ejecutando el comando «kubectl get replicationcontroller». También podemos ver la cantidad de réplicas que se necesitaban, la cantidad actual creada y cuántas de ellos están en ejecución. Para ver los PODs que fueron creados por el controlador de replicación, se ejecuta el comando «kubectl get parts». Mostrará los tres PODs en ejecución. Tenga en cuenta que todos ellos comienzan con el nombre del controlador de replicación, que es mi «muapp-rc», lo que indica que todos fueron creados automáticamente por el mismo controlador de replicación.
Conjunto de réplicas
Para el conjunto de réplicas, es muy similar al controlador de replicación, también tiene las cuatro secciones habituales (apiVersion, kind, metadata y spec). El valor para la versión de API es un poco diferente: «apps/v1». Si te equivocas es probable que se produzca un error que indica que no coincide con «kind» de tipo «ReplicaSet» que es el dato que se pone en el siguiente apartado. En «metadata» agregamos «name» y «labels» igual que en anteriores ocasiones. En la sección «spec» también tendremos la definición del POD a replicar y la cantidad de replicas a crear, igual que para el controlador de replicación.
La diferencia importante entre el controlador de replicación y el conjunto de réplicas es la necesidad de un parametro llamado «selector» que ayuda al conjunto de réplicas a identificar qué partes se encuentran controlados por él. El conjunto de réplicas también puede administrar PODs que no se crearon como parte de la réplica. Se definen estos PODs por sus labels:
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: myapp-replicaset
labels:
app: myapp
type: front-end
spec:
template:
metadata:
name: myapp-pod
labels:
app: myapp
type: front-end
spec:
containers:
- name: nginx-container
image: nginx
replicas: 3
selector:
matchLabels:
type: front-end
El selector no es un campo obligatorio en el caso de un controlador de replicación, pero es también está disponible. El selector de conjunto de réplicas también ofrece muchas otras opciones para hacer coincidir etiquetas.
Etiquetas y selectores
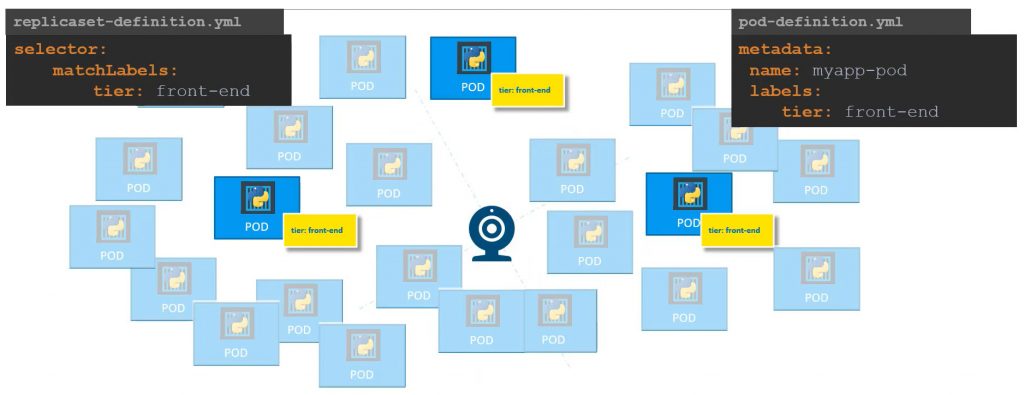
Veamos un ejemplo para entender la relación entre etiquetas y selectores. Supongamos que implementamos tres instancias de una aplicación web en tres PODs. Nos gustaría crear un controlador de replicación o un conjunto de réplicas para garantizar que tengamos tres partes activas en cualquier momento. Entonces se puede usar para monitorizar partes existentes si ya estaban creadas o, en caso de que no se hayan creado, el conjunto de réplicas las creará. La función del conjunto de réplicas es monitorizar las partes y, si alguna de ellas falla, implementar nuevas.
Para que sepa qué PODs monitorizar, ya que podría haber cientos de PODs en el clúster que ejecutan diferentes aplicaciones, es donde entran en juego las etiquetas. Podríamos proporcionar estas etiquetas como un filtro para el conjunto de réplicas en la sección «selector» para que de esta manera, el conjunto de réplicas sepa qué partes monitorizar. El mismo concepto de etiquetas y selectores se usa en muchos otros lugares de Kubernetes. En el momento de ejecutar la replica ya hay suficientes PODs creados que coinciden con las etiquetas definidas, entonces el controlador de replicación no implementará una nueva instancia de POD.
Escalar el conjunto de réplicas.
Si hemos comenzado con tres réplicas y en el futuro decidimos escalar a seis hay varias formas de actualizar el conjunto de réplicas.
El primero es actualizar el número de réplicas en el archivo de definición a seis, luego ejecutar el comando «kubectl replace -f replicaset-definition.yml».
La segunda forma de hacerlo es ejecutar el comando «kubectl scale –replicas=6 -f replicaset-definition.yml»
Otra forma es ejecutar el comnado «kubectl scale –replicas=6 replicaset myapp-replicaset»
En las dos últimas opciones el archivo no se modifica, por lo que si en un futuro vuelve a ejecutarlo, el número de réplica será de nuevo el original.
También hay opciones disponibles para escalar automáticamente el conjunto de réplicas en función de la carga, pero ese es un tema avanzado
Resumen de comandos de replicación en Kubernetes
- Creación: kubectl create -f replicaset-definition.yml –> Comando de creación de un conjunto de réplicas o cualquier objeto en Kubernetes.
- Listado: kubectl get replicaset –> Muestra la lista de conjuntos de réplicas creados
- Borrado: kubectl delete replicaset myapp-replicaset –> Elimina un conjunto de réplica y todos los PODs que controla
- Edición: kubectl replace -f replicaset-definition.yml –> Reemplaza o actualizar el conjunto de réplica y también el conjunto de réplica d
- Escalado: kubectl scale –replicas=6 -f replicaset-definition.yml –> Escala de control de replicas
Más información en https://kubernetes.io/es/docs/concepts/workloads/controllers/replicationcontroller/


