
Despliegues en Kubernetes
En este artículo hablaremos sobre los despliegues en Kubernetes. Por un rato dejaremos los PODs y las réplicas y nos centraremos en implementar su aplicación en un entorno de producción. Hay muchos casos en los que nos puede ayudar Kubernetes. Por ejemplo, podemos tener un servidor web que debe implementarse en un entorno de producción. No se necesita una, sino muchas de esas instancias del servidor web en ejecución. Además, cada vez que las versiones más nuevas estén disponibles en el registro de Docker, nos gustaría actualizar las instancias sin problemas. Pero hay que tener en cuenta que no se quieren actualizar todas a la vez ya que puede afectar a los usuarios que acceden.
Es decir, se quieren actualizar una tras otra, una actualización continua. Podría ser también que una de las actualizaciones resultó en un error inesperado y hay que deshacer el cambio. Otro caso puede ser que queramos realizar múltiples cambios en el entorno, como actualizar las versiones subyacentes del servidor web, escalar el entorno o modificar las asignaciones de recursos, etc. No queremos aplicar cada cambio inmediatamente después de ejecutar el comando; si no aplicar una pausa mientras se realicen los cambios y luego reanudar para que todos los cambios se desplieguen juntos.
Todas estas capacidades están disponibles con Kubernetes. Ya sabemos que los PODs que implementan instancias únicas de las aplicaciones están encapsulados. Múltiples PODs se implementan utilizando controladores de replicación o conjuntos de réplicas. Así que ahora es el turno de la implementación, que es un objeto de Kubernetes que ocupa un lugar más alto en la jerarquía. La implementación nos brinda la capacidad de actualizar las instancias subyacentes sin problemas utilizando actualizaciones continuas, deshacer cambios y pausar y reanudar los cambios según sea necesario.
Implementación
Para realizar los despliegues en Kubernetes, al igual que con los componentes anteriores, primero creamos el archivo de definición de la implementación, el contenido del archivo de definición de implementación es similar al archivo de definición del conjunto de réplicas, excepto por el tipo. Si revisamos el contenido del archivo, tiene una versión API que es «apps/v1», metadatos que tienen nombres y etiquetas y una especificación que tiene una plantilla, réplicas y selector. La plantilla tiene una definición de POD dentro de ella.
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp-deployment
labels:
app: myapp
type: front-end
spec:
template:
metadata:
name: myapp-pod
labels:
app: myapp
type: front-end
spec:
containers:
- name: nginx-container
image: nginx
replicas: 3
selector:
matchLabels:
type: front-end
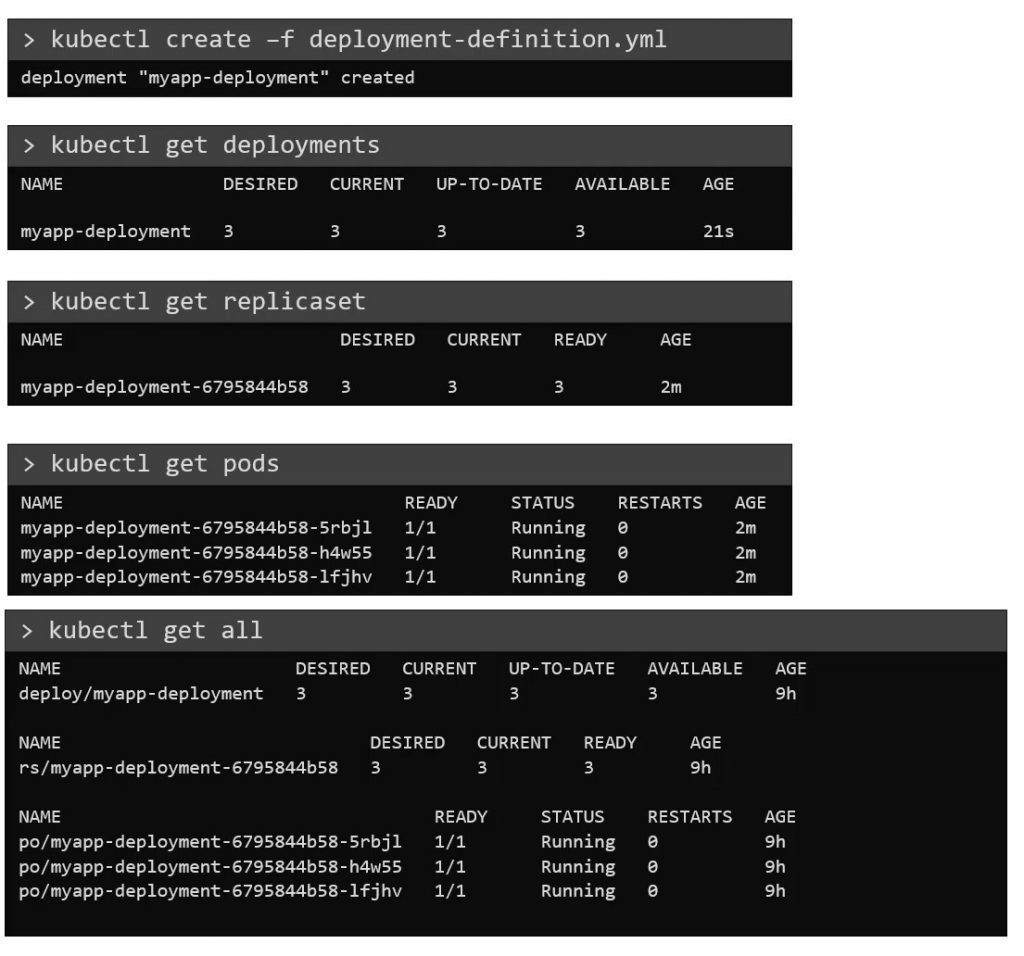 Una vez que el archivo está listo, se ejecuta el comando «kubectl create -f deployment-definition.yml» especificando el archivo de definición de despliegue. Luego se puede ejecutar el comando «kubectl get deployments» para ver el despliegue recién creado. El despliegue crea automáticamente un conjunto de réplicas, por lo que si se ejecuta el comando «kubectl get replicaset», se podrá ver un nuevo conjunto de réplicas con el nombre del despliegue.
Una vez que el archivo está listo, se ejecuta el comando «kubectl create -f deployment-definition.yml» especificando el archivo de definición de despliegue. Luego se puede ejecutar el comando «kubectl get deployments» para ver el despliegue recién creado. El despliegue crea automáticamente un conjunto de réplicas, por lo que si se ejecuta el comando «kubectl get replicaset», se podrá ver un nuevo conjunto de réplicas con el nombre del despliegue.
Los conjuntos de réplica finalmente crean PODs, por lo que ejecutando el comando «kubectl get pods» se pueden ver los POD con el nombre del despliegue y el conjunto de réplicas. Hasta el momento no hay mucha diferencia entre el conjunto de réplicas y los despliegues, excepto por el hecho de que el despliegue creó un nuevo objeto de Kubernetes llamado deployment. Para ver todos los objetos creados a la vez se puede ejecutar el comando «kubectl get all», que mostrará los despliegues creados, el conjunto de réplicas y los tres PODs que se crearon como parte del despliegue. Con más detalle se puede ejecutar «kubectl describe deployment»
Actualización y vuelta atrás
Cuando se crean despliegues en Kubernetes por primera vez, se desencadena un objeto «deployment». Cada despliegue nuevo crea una nueva revisión del objeto «deployment», así que llamemos a la primera, revisión 1. Cuando la aplicación se actualice, es decir, cuando la versión del contenedor se actualice a una nueva, se desencadenará una nueva implementación y se creará una nueva revisión de despliegue llamada revisión 2. Esto nos ayuda a realizar un seguimiento de los cambios realizados en nuestros despliegues y nos permite volver a una versión anterior si es necesario. Se puede ver el estado de un despliegue ejecutando el comando «kubectl rollout status <despliegue>» seguido del nombre del despliegue. Para mostrará las revisiones y el historial se ejecuta el comando «kubectl rollout history <despliegue>» seguido del nombre del despliegue.
Hay dos tipos de estrategias. Si, por ejemplo, se tienen cinco réplicas de su instancia de aplicación web implementada. Una forma de actualizarlos a una versión más nueva es destruirlos y luego crear una versión más nueva de las instancias de la aplicación. Lo que significa es destruir las cinco instancias en ejecución y luego implementar cinco nuevas instancias de la nueva versión de la aplicación. El problema es que durante el período posterior a la caída de las versiones anteriores y antes de que una versión nueva esté activada, la aplicación está inactiva y no es accesible para los usuarios. Esta estrategia se conoce como «Recreación» y, afortunadamente, no es la estrategia de despliegue predeterminada.
La segunda estrategia es donde no los destruimos todos a la vez. Eliminamos la versión anterior y presentamos una versión más nueva una por una. De esta manera, la aplicación nunca se cae y la actualización es perfecta. Esta estrategia de «Actualización continua» es la estrategia de despliegue predeterminada.
Actualización
Cuando se habla de actualizar, podrían ser cosas diferentes. Se puede actualizar la versión de una aplicación, la versión de los contenedores, sus etiquetas, el número de réplicas, etc. Como ya tenemos un archivo de definición de despliegue, es fácil para nosotros modificar estos archivos. Una vez que hacemos los cambios necesarios, ejecutamos el comando «kubectl apply -f <despliegue>» para aplicar los cambios, creando una nueva revisión del despliegue. También se puede usar el comando «kubectl set image <despliegue>» para actualizar la imagen de la aplicación, pero hacerlo de esta manera hace que el archivo de definición del despliegue no esté acorde con lo desplegado.
Para ver la diferencia entre las estrategias de recreación y de actualización continua se puede ejecutar el comando «kubectl describe». Con ella se puede ver la información detallada sobre los despliegues. Cuando se usa la estrategia de recreación, los eventos indican que el antiguo conjunto de réplica se redujo a cero primero. Luego los nuevos conjuntos de réplica se escalan hasta cinco. Sin embargo, cuando se usa la estrategia de actualización continua, el antiguo conjunto de réplicas se redujo en uno cada vez. Luego se van ampliando simultáneamente el nuevo conjunto de réplicas de una en una.
Cuando se crea un nuevo despliegue, primero se crea un conjunto de réplicas automáticamente. A a su vez se crea la cantidad de PODs necesarios para cumplir con la cantidad de réplicas. Cuando se actualiza el objeto «deployment» de kubernetes, se crea un nuevo conjunto de réplicas en segundo plano. Y luego comienza a implementar los contenedores allí al mismo tiempo que elimina los PODs en el antiguo conjunto de réplicas. Sigue así una estrategia de actualización continua. Esto se puede ver cuando intenta enumerar los conjuntos de réplicas utilizando el comando «kubectl get replicaset».
Revertir un cambio realizado en los despliegues en Kubernetes
Si, una vez que se actualiza la aplicación, nos damos cuenta que algo no está bien con la nueva versión y se quiere revertir la actualización. Las implementaciones de Kubernetes le permiten retroceder a una revisión anterior para deshacer el cambio. Se ejecuta el comando «kubectl rollout undo <despliegue>» destruirá el POD en el nuevo conjunto de réplicas y traerá las más antiguas al conjunto de réplicas. Así la aplicación vuelve a su formato anterior. Cuando se compara la salida del comando «kubectl get replicaset» antes y después de revertir se nota esta diferencia. Antes de la reversión, el primer conjunto de réplicas tenía 0 PODs y las nuevas réplicas tenían cinco pods siendo al contrario cuando finaliza la reversión.
Cuando utilizamos el comando «kubectl run» para crear un POD, este comando crea un despliegue y no solo un POD. Esta es la razón por la cual el resultado del comando dice que se creó el «deployment». Solo es una forma de crear un despliegue especificando solo el nombre de una imagen y no usar un archivo de definición. El conjunto de réplica necesario y los PODs se crean automáticamente en el backend. Pero siempre se recomienda usar un archivo de definición, ya que así se puede guardar el archivo, consultarlo en el repositorio de código y modificarlo más tarde según sea necesario.
- Creación: «kubectl create -f deployment-definition.yml»
- Listado: «kubectl get deployments»
- Actualización «kubectl apply -f deployment-definition.yml» y «kubectl set image deployment/myapp-deployment nginx=nginx:1.9.1»
- Información: «kubectl rollout status deployment/myapp-deployment» y «kubectl rollout history deployment/myapp-deployment»
- Rollback: «kubectl rollout undo deployment/myapp-deployment»
Más información en https://kubernetes.io/es/docs/concepts/workloads/controllers/deployment/


