
Regresión lineal Vs. regresión logística
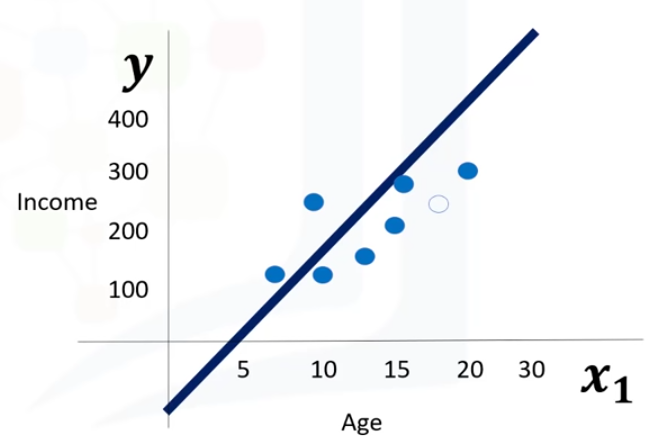 Vamos a ver la diferencia entre la regresión lineal vs. la regresión logística. Revisaremos la regresión lineal y veremos por qué no se puede utilizar correctamente para algunos problemas de clasificación binaria.
Vamos a ver la diferencia entre la regresión lineal vs. la regresión logística. Revisaremos la regresión lineal y veremos por qué no se puede utilizar correctamente para algunos problemas de clasificación binaria.
El objetivo de la regresión logística consiste en construir un modelo para predecir la clase de cada observación, y también la probabilidad de que cada muestra pertenezca a una clase. Idealmente, queremos construir un modelo,  , que pueda estimar que la clase de una observación sea 1, dadas sus características,
, que pueda estimar que la clase de una observación sea 1, dadas sus características,  . Hay que anotar que «
. Hay que anotar que « » son los «vectores de etiquetas» también llamados «valores reales» que nos gustaría predecir, y que «» es el vector de los valores pronosticados por nuestro modelo.
» son los «vectores de etiquetas» también llamados «valores reales» que nos gustaría predecir, y que «» es el vector de los valores pronosticados por nuestro modelo.
Cómo funciona la regresión lineal
Con la regresión lineal, se puede encajar una línea o polinomio a través de los datos. Podemos encontrar esta línea usando el entrenamiento de nuestro modelo, o calculándola matemáticamente basádonos en conjuntos de ejemplo. Por simplificar, vamos a decir que es una línea recta que tiene una ecuación  . Ahora, utilizamos esta línea para predecir un valor continuo ««.
. Ahora, utilizamos esta línea para predecir un valor continuo ««.
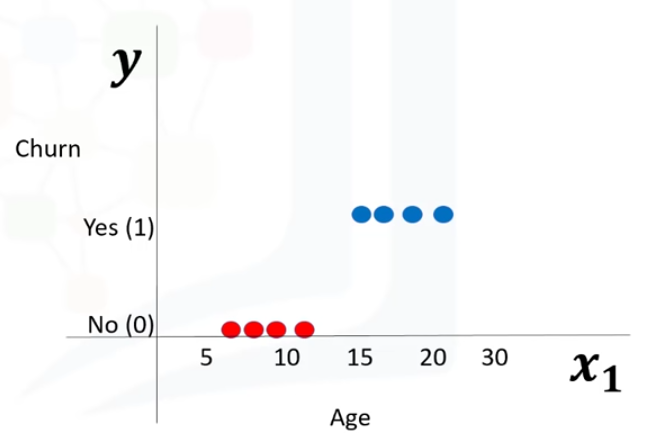 Pero, ¿podemos utilizar la misma técnica para predecir un campo categórico? Tenemos una característica,
Pero, ¿podemos utilizar la misma técnica para predecir un campo categórico? Tenemos una característica,  , y una característica categórica con dos clases: por ejemplo «si» y «no». Podemos correlacionar «si» y «no» con valores enteros, 0 y 1. Gráficamente, podríamos representar nuestro conjunto de datos con un gráfico de dispersión. Pero esta vez sólo tenemos 2 valores para el eje y. Con la regresión lineal se puede encajar de nuevo un polinomio a través de los datos, que se muestra tradicionalmente como
, y una característica categórica con dos clases: por ejemplo «si» y «no». Podemos correlacionar «si» y «no» con valores enteros, 0 y 1. Gráficamente, podríamos representar nuestro conjunto de datos con un gráfico de dispersión. Pero esta vez sólo tenemos 2 valores para el eje y. Con la regresión lineal se puede encajar de nuevo un polinomio a través de los datos, que se muestra tradicionalmente como  . Este polinomio también se puede mostrar tradicionalmente como
. Este polinomio también se puede mostrar tradicionalmente como  . Esta línea tiene 2 parámetros, que se muestran con el vector
. Esta línea tiene 2 parámetros, que se muestran con el vector  , donde los valores del vector son
, donde los valores del vector son  y
y  . También podemos mostrar la ecuación de esta línea formalmente como
. También podemos mostrar la ecuación de esta línea formalmente como  . Y, en general, podemos mostrar la ecuación de un espacio multidimensional como
. Y, en general, podemos mostrar la ecuación de un espacio multidimensional como  , donde
, donde  son los parámetros de la línea en un espacio bidimensional, o parámetros de un plano en un espacio tri-dimensional, y así sucesivamente. Como
son los parámetros de la línea en un espacio bidimensional, o parámetros de un plano en un espacio tri-dimensional, y así sucesivamente. Como ![\theta^T=\left [ \theta_0, \theta_1, \theta_2, \cdots \right ]](https://www.statdeveloper.com/wp-content/ql-cache/quicklatex.com-0435d4d5c49d79a40c47636f37c66418_l3.png "Rendered by QuickLaTeX.com") es un vector de parámetros, y se supone que para ser multiplicado por
es un vector de parámetros, y se supone que para ser multiplicado por  , se muestra convencionalmente como
, se muestra convencionalmente como  . también se llama el «vector de peso» o «confianzas de la ecuación», siendo estos dos términos usados indistintamente. Y
. también se llama el «vector de peso» o «confianzas de la ecuación», siendo estos dos términos usados indistintamente. Y  es el conjunto de características, que representa una observación. De todos modos, dado un conjunto de datos, todos los conjuntos de características , parámetros, se pueden calcular a través de un algoritmo de optimización o matemáticamente, que resulta en la ecuación de la línea adecuada.
es el conjunto de características, que representa una observación. De todos modos, dado un conjunto de datos, todos los conjuntos de características , parámetros, se pueden calcular a través de un algoritmo de optimización o matemáticamente, que resulta en la ecuación de la línea adecuada.
Por ejemplo, si los parámetros de esta línea son ![\theta^T=\left [ -1, 0.1 \right ]](https://www.statdeveloper.com/wp-content/ql-cache/quicklatex.com-8d1047ffa3e044c6e8e033fb8eacd34c_l3.png "Rendered by QuickLaTeX.com") , entonces la ecuación de la línea es
, entonces la ecuación de la línea es  . Ahora, podemos utilizar esta línea de regresión para predecir. Por ejemplo, para un valor de 13 tenemos:
. Ahora, podemos utilizar esta línea de regresión para predecir. Por ejemplo, para un valor de 13 tenemos:  . Ahora podemos definir un umbral, por ejemplo, en 0.5, para definir la clase. Así que escribimos una regla para nuestro modelo, , que nos permite separar la clase 0 de la clase 1. Si el valor de
. Ahora podemos definir un umbral, por ejemplo, en 0.5, para definir la clase. Así que escribimos una regla para nuestro modelo, , que nos permite separar la clase 0 de la clase 1. Si el valor de  es menor que 0.5, entonces la clase es 0, de lo contrario, si el valor de es más de 0.5, entonces la clase es 1. Y debido a que el valor «» de nuestro ejemplo es menor que el umbral, podemos decir que pertenece a la clase 0, basada en nuestro modelo.
es menor que 0.5, entonces la clase es 0, de lo contrario, si el valor de es más de 0.5, entonces la clase es 1. Y debido a que el valor «» de nuestro ejemplo es menor que el umbral, podemos decir que pertenece a la clase 0, basada en nuestro modelo.
Pero aquí hay un problema, ya que no es el mejor modelo para conocer la probabilidad de pertenencia a la clase. Además, si utilizamos la línea de regresión para calcular la clase de un punto, siempre devuelve un número independientemente de lo grande o pequeño, positivo o negativo que es la entrada. Así utilizando el umbral, podemos encontrar la clase de un registro sin importar lo grande que sea el valor, siempre que sea mayor que 0.5, simplemente es igual a 1. Y viceversa, independientemente de lo pequeño que sea el valor, la salida sería cero si es menor que 0.5. En otras palabras, no hay diferencia entre un valor de uno o de 1000; el resultado sería 1. Este método no nos da realmente la probabilidad de que una observación pertenezca a una clase, lo cual es muy deseable. Así que necesitamos un método que también nos pueda dar la probabilidad de caer en una clase.
Función sigmoide
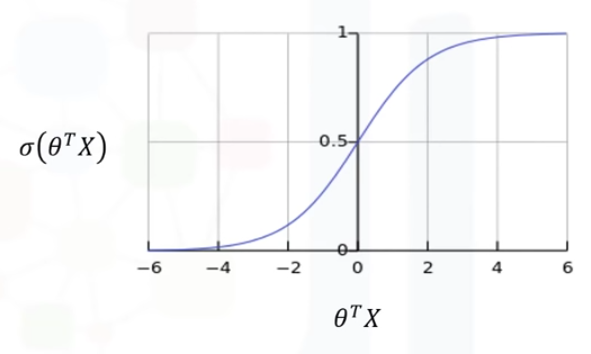 Si en vez de usar usamos una función específica llamada sigmoide (
Si en vez de usar usamos una función específica llamada sigmoide ( ), entonces,
), entonces,  nos da la probabilidad de que un punto pertenezca a una clase, en lugar del valor de directamente. En lugar de calcular el valor de directamente, devuelve la probabilidad de que un sea muy grande o muy pequeño. Siempre devuelve un valor entre 0 y 1 dependiendo de que tan grande es
nos da la probabilidad de que un punto pertenezca a una clase, en lugar del valor de directamente. En lugar de calcular el valor de directamente, devuelve la probabilidad de que un sea muy grande o muy pequeño. Siempre devuelve un valor entre 0 y 1 dependiendo de que tan grande es  realmente.
realmente.
Ahora, nuestro modelo es  , que representa la probabilidad de que la salida sea 1, dado . La función sigmoide, también llamada la función logística, se asemeja a la función de paso y se utiliza la siguiente expresión en la regresión logística:
, que representa la probabilidad de que la salida sea 1, dado . La función sigmoide, también llamada la función logística, se asemeja a la función de paso y se utiliza la siguiente expresión en la regresión logística:

Fíjese en que en la ecuación sigmoide, cuando  se hace muy grande, el
se hace muy grande, el  en el denominador de la fracción se convierte en casi cero, y el valor de la función sigmoid se acerca más a 1. Si es muy pequeño, la función sigmoide se acerca a cero. Representando en el trazado sigmoide, cuando , se hace más grande, el valor de la función sigmoide se acerca a 1, y también, si el es muy pequeño, la función sigmoide se acerca a cero. Por lo tanto, el valor de la función sigmoide está entre 0 y 1, lo que hace que sea apropiado para interpretar los resultados como probabilidades. Es obvio que cuando el resultado de la función sigmoide se acerca más a 1, la probabilidad de , dado , sube, y en contraste, cuando el valor sigmoide está más cerca de cero, la probabilidad de , dado , es muy pequeña.
en el denominador de la fracción se convierte en casi cero, y el valor de la función sigmoid se acerca más a 1. Si es muy pequeño, la función sigmoide se acerca a cero. Representando en el trazado sigmoide, cuando , se hace más grande, el valor de la función sigmoide se acerca a 1, y también, si el es muy pequeño, la función sigmoide se acerca a cero. Por lo tanto, el valor de la función sigmoide está entre 0 y 1, lo que hace que sea apropiado para interpretar los resultados como probabilidades. Es obvio que cuando el resultado de la función sigmoide se acerca más a 1, la probabilidad de , dado , sube, y en contraste, cuando el valor sigmoide está más cerca de cero, la probabilidad de , dado , es muy pequeña.
Regresión logística
En la regresión logística, modelamos la probabilidad de que una entrada pertenezca a la clase por defecto  , y podemos escribirlo formalmente como,
, y podemos escribirlo formalmente como,  . También podemos escribir
. También podemos escribir  . Por lo tanto, nuestro trabajo es entrenar al modelo para que establezca sus valores de parámetros de tal manera que nuestro modelo es una buena estimación de
. Por lo tanto, nuestro trabajo es entrenar al modelo para que establezca sus valores de parámetros de tal manera que nuestro modelo es una buena estimación de  . De hecho, esto es lo que un buen modelo clasificador construido por regresión logística se supone que debe hacer por nosotros. Además, debe ser una buena estimación de
. De hecho, esto es lo que un buen modelo clasificador construido por regresión logística se supone que debe hacer por nosotros. Además, debe ser una buena estimación de  que se puede mostrar como
que se puede mostrar como  .
.
Vamos a ver cuál es el proceso para lograr el cálculo:
- Inicializar el vector con valores aleatorios, como se hace con la mayoría de los algoritmos de aprendizaje automático.
- Calcular la salida del modelo, que es
 , para una observación de la muestra. La salida de esta ecuación es el valor de la predicción, la probabilidad que el cliente pertenece a la clase 1.
, para una observación de la muestra. La salida de esta ecuación es el valor de la predicción, la probabilidad que el cliente pertenece a la clase 1. - Comparar la salida de nuestro modelo, , con la etiqueta real de la observación. Luego, registre la diferencia como el error de nuestro modelo para esta observación. Este es el error para una sóla observación dentro del conjunto de datos.
- Calcular el error para todas las observaciones tal como lo hicimos en los pasos anteriores, y añadimos estos errores. El error total es el coste del modelo. La función de coste representa la diferencia entre el real y los valores pronosticados del modelo. Por lo tanto, el costo muestra lo mal que se encuentra el modelo estimando las etiquetas del cliente. Por lo tanto, cuanto más bajo es el costo, mejor es el modelo estimando correctamente las etiquetas del cliente. Por lo tanto, lo que queremos hacer es tratar de minimizar este costo.
- Pero, debido a que los valores iniciales para fueron elegidos al azar, es muy probable que la función de coste sea muy alta. Por lo tanto, cambiamos la forma de ser de tal manera que esperemos reducir el coste total.
- Después de cambiar los valores de , volvemos al paso 2.
 , para una observación de la muestra. La salida de esta ecuación es el valor de la predicción, la probabilidad que el cliente pertenece a la clase 1.
, para una observación de la muestra. La salida de esta ecuación es el valor de la predicción, la probabilidad que el cliente pertenece a la clase 1.A continuación, empezamos otra iteración y calculamos de nuevo el coste del modelo. Y seguimos haciendo esos pasos una y otra vez, cambiando los valores de cada vez, hasta que el coste es lo suficientemente bajo. Por lo tanto, esto plantea dos preguntas: ¿Cómo podemos cambiar los valores de de modo que el coste se reduzca en las iteraciones? ¿Cuándo debemos detener las iteraciones?
Hay diferentes maneras de cambiar los valores , pero una de las formas más populares es la ascendencia gradiente. Además, hay varias formas de detener las iteraciones, pero esencialmente se detiene la formación mediante el cálculo de la precisión de su modelo, y detenerlo cuando sea satisfactorio.
Ir al artículo anterior de la serie: Introducción a la Regresión Logística
Ir al artículo siguiente de la serie: Cálculo de los parámetros de la función logística

