
Recomendaciones basado en filtrado colaborativo.
Las recomendaciones basado en filtrado colaborativo se basa en el hecho de que existen relaciones entre productos y los intereses de la gente. Muchos sistemas de recomendaciones utilizan Filtrado colaborativo para encontrar estas relaciones y para dar una recomendación precisa de un producto que el usuario puede que le guste o que le interese. El filtrado colaborativo tiene básicamente dos enfoques: basado en el usuario y basado en artículos.
- El filtrado colaborativo basado en el usuario se basa en la similitud o el vecindario del usuario.
- El filtrado colaborativo basado en artículos se basa en la similaridad entre los articulos.
Recomendaciones de filtrado colaborativo basado en el usuario
En el filtrado colaborativo basado en el usuario, tenemos un usuario activo para el que la recomendación está dirigida. El motor de filtrado colaborativo, primero busca a los usuarios que son similares, es decir, los usuarios que comparten los patrones de calificación del usuario activo. El filtrado colaborativo basa esta similitud en cosas como la historia, la preferencia y las opciones que los usuarios hacen al comprar, observar, o al disfrutar de algo. Por ejemplo, las películas que usuarios similares han calificado altamente. Entonces, utiliza las calificaciones de estos usuarios similares para predecir las posibles calificaciones por parte del usuario activo para una película que no había visto previamente. Por ejemplo, si 2 usuarios son similares o son vecinos, en términos de su interés en las películas, podemos recomendar una película para el usuario activo que su vecino ya ha visto.
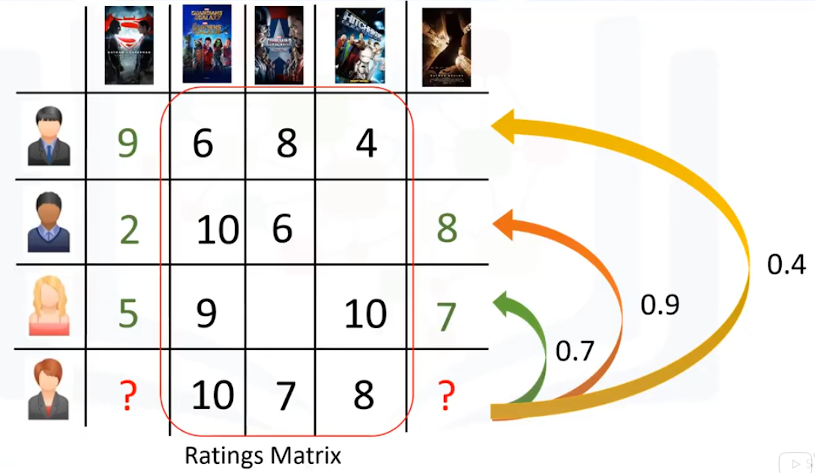 Supongamos que tenemos una matriz simple de ítem de usuario, que muestra las calificaciones de 4 usuarios para 5 diferentes películas. Supongamos también que nuestro usuario activo ha visto y evaluado 3 de estas 5 películas. Vamos a averiguar cuál de las dos películas que nuestro usuario activo no ha visto, debe ser recomendada para el. El primer paso es descubrir lo similar que es el usuario activo a los otros usuarios. Esto se puede hacer a través de muchas técnicas estadísticas y vectoriales, tales como mediciones de distancia o similaridad, incluyendo Distancia Euclidiana, Correlación de Pearson, Similitud de Cosine, etc… Para calcular el nivel de similitud entre 2 usuarios, utilizamos las 3 películas que los usuarios han calificado en el pasado. Independientemente de lo que utilizamos para la medición de similaridad, digamos, por ejemplo, la similitud, podría ser 0.7, 0.9, y 0.4 entre el usario activo y otros usuarios. Estos números representan pesos de similitud, o la proximidad del usuario activo a otros usuarios en el dataset.
Supongamos que tenemos una matriz simple de ítem de usuario, que muestra las calificaciones de 4 usuarios para 5 diferentes películas. Supongamos también que nuestro usuario activo ha visto y evaluado 3 de estas 5 películas. Vamos a averiguar cuál de las dos películas que nuestro usuario activo no ha visto, debe ser recomendada para el. El primer paso es descubrir lo similar que es el usuario activo a los otros usuarios. Esto se puede hacer a través de muchas técnicas estadísticas y vectoriales, tales como mediciones de distancia o similaridad, incluyendo Distancia Euclidiana, Correlación de Pearson, Similitud de Cosine, etc… Para calcular el nivel de similitud entre 2 usuarios, utilizamos las 3 películas que los usuarios han calificado en el pasado. Independientemente de lo que utilizamos para la medición de similaridad, digamos, por ejemplo, la similitud, podría ser 0.7, 0.9, y 0.4 entre el usario activo y otros usuarios. Estos números representan pesos de similitud, o la proximidad del usuario activo a otros usuarios en el dataset.
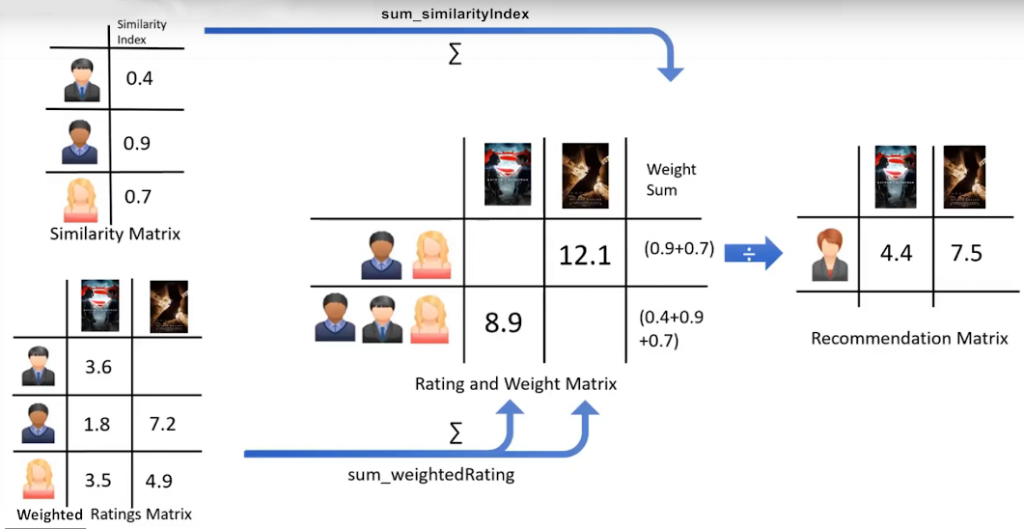
El siguiente paso es crear una matriz de evaluación ponderada. Acabamos de calcular la similaridad de los usuarios a nuestro usuario activo en la diapositiva anterior. Ahora podemos usarlo para calcular la posible opinión del usuario activo acerca de nuestras 2 peliculas objetivo. Esto se logra multiplicando los pesos de similitud a las calificaciones de usuario. Esto da como resultado una matriz de calificaciones ponderada, que representa la opinión de la vecindad del usuario acerca de nuestras 2 películas candidatas para la recomendación. De hecho, incorpora el comportamiento de otros usuarios y da más peso a las calificaciones de los usuarios que son más parecidos al usuario activo. Ahora podemos generar la matriz de recomendaciones mediante la suma de todos los pesos ponderados. Sin embargo, como 3 usuarios calificaron a la primera película potencial, y 2 usuarios calificaron la segunda película, tenemos que normalizar los valores ponderados de la calificación. Lo hacemos dividiéndolo por la suma del índice de similitud para los usuarios. El resultado es la calificación potencial que nuestro usuario activo dará a estas películas, en base a su similitud con otros usuarios. Es obvio que podemos usarlo para clasificar las películas para dar una recomendación a nuestro usuario activo.
Recomendaciones de filtrado colaborativo basado en el artículo
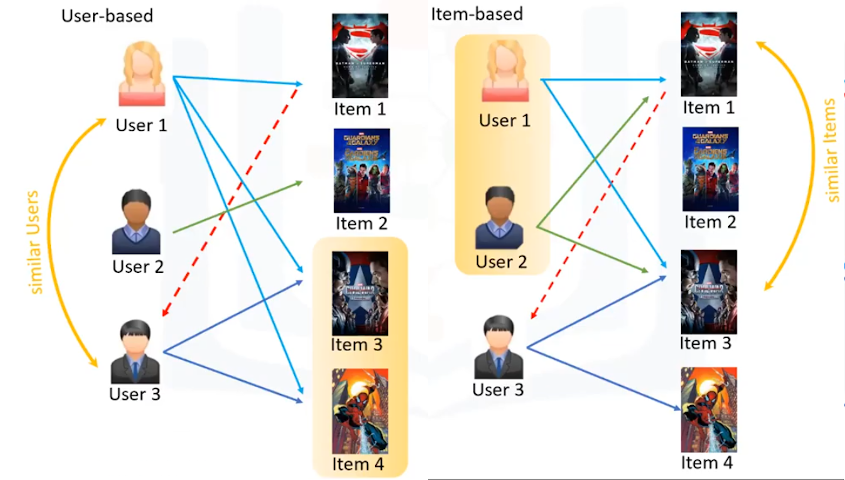
En el enfoque basado en el usuario, la recomendación se basa en los usuarios del mismo vecindario, con el o ella comparte preferencias comunes. Por ejemplo, como el Usuario1 y el Usuario3, a ambos les gustó el artículo 3 y el artículo 4, los consideramos similares o usuarios vecinos, y recomendamos el artículo 1, que es evaluado positivamente por Usuario1 al Usuario3. En el enfoque basado en artículos, los artículos similares crean vecindarios en el comportamiento de los usuarios.
Por ejemplo, el artículo 1 y el artículo 3 se consideran vecinos, ya que fueron valorados positivamente por tanto Usuario1 como Usuario2. Por lo tanto, el artículo 1 se puede recomendar al Usuario3 como él ya ha mostrado interés en el artículo 3. Por lo que, las recomendaciones se basan en los artículos en el vecindario que un usuario puede preferir.
 Inconvenientes
Inconvenientes
 Inconvenientes
InconvenientesEl filtro colaborativo es un sistema de recomendaciones muy eficaz, sin embargo, existen algunos desafíos con él también.
Uno de ellos es la dispersión de datos. La dispersión de datos se produce cuando se dispone de un dataset grande de usuarios, que generalmente sólo califican un número limitado de artículos. Como se ha mencionado, los recomendadores basados en la colaboración sólo puede predecir la puntuación de un artículo si hay otros usuarios que lo han calificado. Debido a la dispersión, es posible que no tengamos calificaciones suficientes en el dataset de artículos de usuario, lo que hace que sea imposible proporcionar recomendaciones adecuadas.
Otra cuestión que hay que tener en cuenta es algo llamado «inicio en frío». El inicio en frío hace referencia a la dificultad del sistema de recomendación tiene cuando hay un nuevo usuario y, como tal, un perfil no existe para ellos todavía. El inicio en frío también puede ocurrir cuando tenemos un nuevo artículo que no ha recibido una calificación.
La escalabilidad también se puede convertir en un problema. A medida que aumenta el número de usuarios o artículos y la cantidad de datos se expande, los algoritmos de filtrado colaborativo comenzarán a sufrir caídas en el rendimiento, simplemente debido al crecimiento en el cálculo de similaridad.
Hay algunas soluciones para cada uno de estos desafíos, tales como el uso de sistemas de recomendación basados en híbridos.
Podemos ver un ejemplo en Python en esta entrada: Recomendaciones basado en filtrado colaborativo en Python
Ir al artículo anterior de la serie: Recomendaciones basado en contenido
