
Evaluación del modelo de regresión
El objetivo al realizar un modelo de regresión es predecir con precisión un caso desconocido. Con este fin, tenemos que realizar una evaluación del modelo de regresión después de crear el modelo. Para realizarlo podemos usar el entrenamiento y la prueba en el mismo conjunto de datos. También podemos realizar una división del conjunto de datos para entrenamiento y otro para prueba.
La primera solución consiste en seleccionar una parte de nuestro conjunto de datos para la realización de pruebas. Usamos todo el conjunto de datos para el entrenamiento, y construimos un modelo usando este conjunto de entrenamiento. Luego seleccionamos una pequeña porción del conjunto de datos, que se utiliza como valores reales del conjunto de pruebas. Pasamos este conjunto por nuestro modelo construido, pronosticando valores. Por último, comparamos los valores pronosticados por nuestro modelo con los valores reales.
Modelo Train/Test Split
Una forma de mejorar la precisión fuera de la muestra consiste en utilizar otro enfoque de evaluación denominado «Train/Test Split» (División entre entrenamiento y prueba). En este enfoque, seleccionamos una parte de nuestro conjunto de datos para entrenamiento y el resto se utiliza para probar. El modelo se basa en el conjunto de formación y luego se pasa para la predicción. Finalmente, los valores pronosticados para el conjunto de pruebas se comparan con los valores reales del conjunto de datos. Este modelo implica la división del conjunto de datos en conjuntos de formación y pruebas, respectivamente, que son mutuamente excluyentes. Esto proporcionará una evaluación más precisa sobre la precisión de fuera de la muestra, ya que la prueba del conjunto de datos NO forma parte del conjunto de datos que se ha utilizado para formar los datos.
Este modelo depende de los conjunto de datos en los que los datos fueron formados y probados. Así que aún tiene algunos problemas debido a esta dependencia. Otro modelo de evaluación, denominado «k-fold cross-validation», soluciona la mayoría de estos problemas. Este modelo se basa en hacer k-veces el modelo «Train/Test Split» y luego promediando la precisión. Supongamos que hemos tomado la decisión de realizar 4 pruebas de tipo «Train/Test Split», para cada una de ellas tomaremos 1/4 de todo el conjunto de datos como datos para las pruebas, y el resto para la formación del modelo. Se evalua la precisión para cada uno de los modelos y finalmente se calcula el promedio de precisón.
Evaluación del modelo
Hay diferentes métricas de la evaluación del modelo de regresión, pero la mayoría de ellos se basan en la similitud de los valores pronosticados y reales. Una de las métricas más simples para calcular la precisión de nuestro modelo
de regresión es el error calculado como la diferencia promedio entre los valores predichos y los reales para todas las filas.
En un sentido general, cuando se prueba con un conjunto de datos en el que se conoce el valor objetivo para cada dato puntual, es capaz de obtener un porcentaje de predicciones exactas para el modelo. Este enfoque de evaluación probablemte tendría una alta «precisión de formación» y una baja «precisión fuera de la muestra», ya que el modelo conoce todos los datos de prueba.
La precisión de la formación es el porcentaje de predicciones correctas que hace el modelo cuando se utiliza el conjunto de datos de prueba. Sin embargo, una alta precisión en la formación no es necesariamente algo bueno, ya que puede dar como resultado un sobreajuste de los datos, un modelo que puede estar mostrando ruido y producir un modelo no generalizado.
La precisión fuera de la muestra es el porcentaje de las predicciones correctas que el modelo realiza sobre datos que NO ha sido formado el modelo. Si hacemos «formación y prueba» en el mismo conjunto de datos probablemente el modelo tendrá una precisión baja fuera de la muestra.
Es importante que nuestros modelos tengan una precisión alta, fuera de la muestra, ya que deben hacer predicciones correctas sobre datos desconocidos.
Metricas de evaluación
Antes de poder definir las diferentes métricas utilizadas para evaluar la regresión, tenemos que definir lo que realmente es un error: el error de un modelo de regresión es la diferencia entre los datos puntuales y la línea de tendencia generada por el algoritmo.
Un error puede ser determinado de multiples maneras:
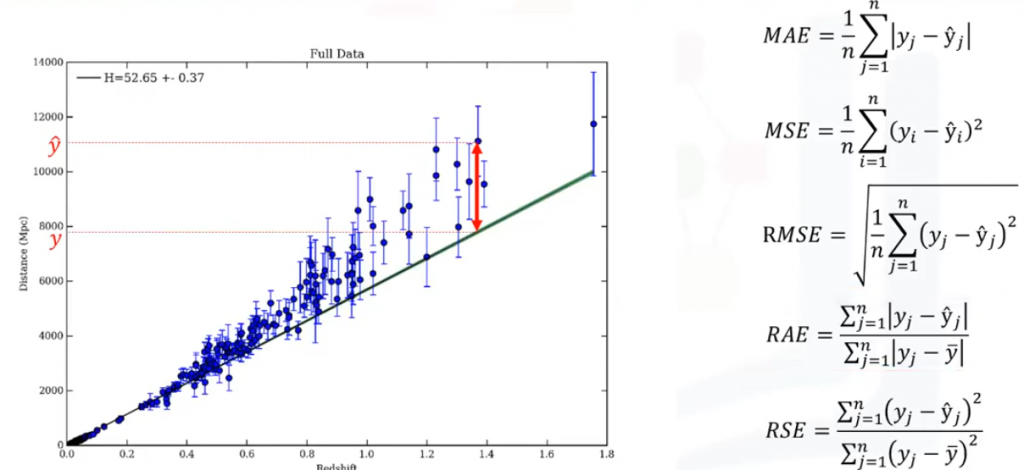
- Error medio absoluto (MAE) es la media del valor absoluto de los errores. Es la medida más fácil de entender, ya que es sólo el error promedio.
- Error cuadrático medio (MSE) es la media de los errores al cuadrado. Es más popular que el error medio absoluto porque el enfoque se orienta más hacia grandes errores. Esto se debe a que el término al cuadrado aumenta exponencialmente los errores más grandes en comparación con los más pequeños.
- Raiz cuadrada del error cuadrático medio (RMSE) es la raíz cuadrada de la anterior medida. Esta es una de las métricas más populares de las métricas de evaluación porque es interpretable en las mismas unidades que el vector de respuesta (o unidades
 ) haciendo fácil de correlacionar con la información.
) haciendo fácil de correlacionar con la información. - Error absoluto relativo (RAE), también conocido como la suma residual de cuadrado, donde la barra de es un valor medio de , toma el error absoluto total y la normaliza dividiendo por el error absoluto total del predictor simple.
- Error cuadrático relativo (RSE) es muy similar a «Error absoluto relativo», pero se usa para calcular R-cuadrado. R-cuadrado no es un error, si no, una métrica popular para la precisión de su modelo. Representa como de cerca están los valores de los datos de la línea de regresión ajustada. Cuanto más alto sea el R-cuadrado, mejor encaja el modelo a los datos.
 ) haciendo fácil de correlacionar con la información.
) haciendo fácil de correlacionar con la información.
Cada una de estas métricas se puede utilizar para cuantificar la predicción. La elección de la métrica depende del tipo de modelo, el tipo de datos y el dominio del conocimiento.
Ir al artículo anterior de la serie: Regresión lineal múltiple
Ir al artículo siguiente de la serie: Regresión no lineal

