
Introducción a los árboles de decisión
 Para ver una introducción a los árboles de decisión, imagina que eres un investigador médico que compila datos para un estudio. Ya has recolectado datos sobre un conjunto de pacientes, los cuales sufrieron de la la misma enfermedad. Durante el curso de su tratamiento, cada paciente respondió a uno de los dos medicamentos; nosotros los llamaremos fármaco A y fármaco B. Tu trabajo consiste en construir un modelo para encontrar qué medicamento podría ser apropiado para un paciente futuro con la misma enfermedad. Los conjuntos de características de este dataset son edad, género, presión sanguinea y colesterol de nuestro grupo de pacientes, y el objetivo es el fármaco al que cada paciente respondió.
Para ver una introducción a los árboles de decisión, imagina que eres un investigador médico que compila datos para un estudio. Ya has recolectado datos sobre un conjunto de pacientes, los cuales sufrieron de la la misma enfermedad. Durante el curso de su tratamiento, cada paciente respondió a uno de los dos medicamentos; nosotros los llamaremos fármaco A y fármaco B. Tu trabajo consiste en construir un modelo para encontrar qué medicamento podría ser apropiado para un paciente futuro con la misma enfermedad. Los conjuntos de características de este dataset son edad, género, presión sanguinea y colesterol de nuestro grupo de pacientes, y el objetivo es el fármaco al que cada paciente respondió.
Es una muestra de clasificadores binarios, y se puede utilizar la parte de entrenamiento del dataset para construir un árbol de decisiones, y luego, usarlo para predecir la clase de un paciente desconocido … en esencia, para llegar a una decisión sobre qué medicamento se debería recetar a un nuevo paciente.
creación de un árbol de decisiones
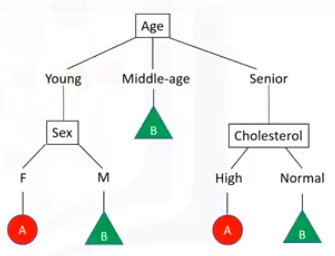
Los árboles de decisión se crean dividiendo el conjunto entrenado en nodos distintos, donde un nodo contiene todo, o la mayoría, de una categoría de los datos. Así que, si queremos recetar un medicamento a un nuevo paciente, debemos tener en cuenta la situación del paciente. Empezamos con la Edad, el cual puede ser Joven, Mediana Edad o Mayor. Si el paciente es de mediana edad, entonces iremos por el fármaco B. Por otro lado, si el paciente es joven o mayor, necesitaremos más detalles para ayudarnos a decidir que medicamento recetar. Las variables de decisión adicionales pueden ser cosas tales como los niveles de colesterol, sexo o presión sanguínea. Por ejemplo, si el paciente es femenino, entonces recomendaremos el fármaco A, pero si el paciente es masculino, entonces iremos por el fármaco B. Como puedes ver, los árboles de decisión tratan sobre probar un atributo y ramificar los casos, basándose en el resultado de la prueba.
- Cada nodo interno corresponde a una prueba.
- Cada rama se corresponde con un resultado de la prueba.
- Cada nodo de hoja asigna un paciente a una clase.
Se puede construir un árbol de decisiones teniendo en cuenta los atributos uno por uno. En primer lugar, elije un atributo de nuestro dataset. Calcula la importancia del atributo en la división de los datos. Más adelante explicaremos cómo calcular la importancia de un atributo, para ver si se trata de un atributo efectivo o no. A continuación, divide los datos en función del valor del mejor atributo. Luego, ve a cada rama y repitelo para el resto de los atributos. Después de construir este árbol, puede usarlo para predecir la clase de casos desconocidos o, en nuestro caso, el fármaco adecuado para un nuevo paciente basado en su caracterestica.
Ir al artículo anterior de la serie: Evaluación del modelo de clasificación
Ir al artículo siguiente de la serie: Construyendo árboles de decisión

