
Clustering DBSCAN
DBSCAN es un algoritmo de clustering basado en la densidad, que es apropiado utilizar al examinar datos espaciales.
La mayoría de las técnicas tradicionales de clustering, tales como k-Means, jerárquicas, y el fuzzy clustering, se puede utilizar para agrupar datos de una forma no supervisada. Sin embargo, cuando se aplica a tareas con clusteres de forma arbitraria, o clusteres dentro de clusteres, las técnicas tradicionales podrían no ser capaces de lograr buenos resultados. Es decir, los elementos en el mismo cluster pueden no compartir suficiente similitud, o el rendimiento puede ser pobre. Además, si bien los algoritmos basados en particiones, como K-Means, pueden ser fáciles de entender e implementar en la práctica, el algoritmo no tiene noción de valores atípticos. Es decir,todos los puntos se asignan a un cluster, incluso si no pertenecen a ninguno. En el dominio de la detección de anomalías, esto ocasiona problemas como puntos anómalos que se asignarán en el mismo cluster que los puntos de datos «normales». Los puntos anómalos atraen al centroide del cluster hacia ellos, haciendo más difícil de clasificarlos como puntos anómalos. En contraste, el clustering basado en Densidad localiza regiones de alta densidad que están separadas una de la otra por regiones de baja densidad. Densidad, en este contexto, se define como el número de puntos dentro de un radio especificado. Un tipo específico y muy popular de clustering basado en la densidad es DBSCAN.
DBSCAN es especialmente eficaz para tareas como la identificación de clases en un contexto espacial. El atributo maravilloso del algoritmo DBSCAN es que puede encontrar cualquier forma arbitraria de cluster sin verse afectado por el ruido. Además puede encontrar la parte más densa de las muestras centradas en datos, ignorando áreas menos densas o ruidos.
Cómo funciona DBSCAN
DBSCAN significa «Density-based Spatial Clustering of Applications with Noise» (Clustering espacial basado en densidad de aplicaciones con ruido). Esta técnica es una de las más comunes de algoritmos de clustering, que funciona en base a la densidad del objeto. DBSCAN trabaja en la idea de que si un punto en particular pertenece a un cluster, debería estar cerca de un montón de otros puntos en ese cluster.
Funciona en base a 2 parámetros: Radio y Puntos Mínimos.
El radio, R, determina una longitud específica que, si incluye suficientes puntos dentro de él, lo llamamos de «Área densa». Los Puntos Mínimos, M, determina la cantidad mínima de datos que queremos alrededor de otra observación para definir un cluster.
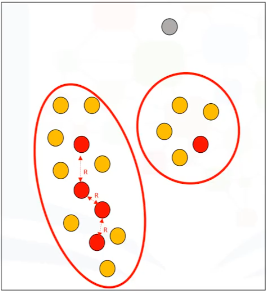
Por ejemplo, definamos el radio de 2 unidades y fijemos que el punto mínimo sea de 6, incluyendo el punto de interés. Para ver cómo funciona DBSCAN, tenemos que determinar el tipo de puntos. Cada punto de nuestro conjunto de datos puede ser un punto central (core), fronterizo (border) o atípico (outlier). Toda la idea detrás del algoritmo DBSCAN es visitar cada punto, y encontrar su tipo. A continuación, agrupamos los puntos como clusteres en función de sus tipos.
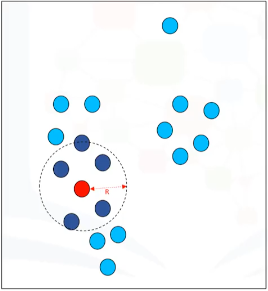
Dado un punto al azar. Primero revisamos para ver si es un punto de datos central. Un punto de datos es core si, dentro de la R-vecindad de este punto, hay al menos M puntos. Por ejemplo, ya que hay 6 puntos en el vecindario de 2 centímetros del punto rojo, marcamos este punto como un punto central.
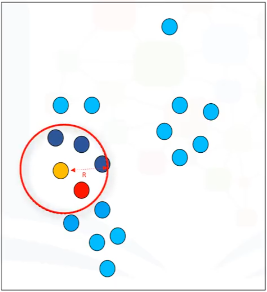
Veamos otro punto. Este sólo tiene 5 puntos en su vecindario, incluyendo el punto amarillo. Entonces, se trata de un punto «fronterizo». Un punto de datos es un punto border si cuple estas condiciones:
- Su vecindario contiene menos de M puntos de datos
- Se puede acceder desde algún punto central. Es decir, que dentro de su R-distancia hay un punto central
Esto significa que a pesar de que el punto amarillo se encuentra dentro del vecindario de 2 centímetros del punto rojo, no es por sí mismo un punto central, porque no tiene por lo menos 6 puntos en su vecindario.
Seguimos con el siguiente punto. Como se puede ver, también es un punto central. Y todos los puntos en torno a él, que no son puntos centrales, son puntos fronterizos.
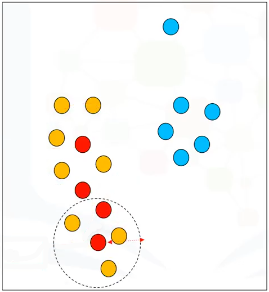
Tomemos este punto. Puede ver que no es un punto central, ni tampoco es un punto fronterizo. Así que, lo etiquetaremos como un valor atípico. Un valor atípico es un punto que: no es un punto central, y tampoco está lo suficientemente cerca como para ser accesible desde un punto central.
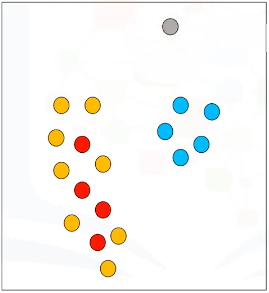
Seguimos y visitamos todos los puntos del conjunto de datos y los etiquetamos como Centrales, Fronterizos, o Atípicos.
El siguiente paso es conectar los puntos centrales que son vecinos, y colocarlos en el mismo cluster. Por lo tanto, un cluster se forma con al menos un punto central, además de todos los puntos centrales accesibles, además de todas sus puntos fronterizos.
Resumiendo
DBSCAN puede encontrar clusteres en forma arbitraria. Incluso puede encontrar un cluster completamente rodeado por un cluster diferente. DBSCAN tiene una noción de ruido, y es robusto a los valores atípicos. Además de eso, DBSCAN hace que sea muy práctico para usarse en muchos de los problemas reales del mundo porque no requiere que se especifique el número de clusteres, como por ejemplo K en K-Medias. Todo esto puede realizarse con Python, donde puede ver un ejemplo en esta entrada: Clustering DBSCAN en Python
Ir al artículo anterior de la serie: Agrupación en clúster jerárquica
Ir al artículo siguiente de la serie: Introducción a los sistemas de recomendación

