
Docker Orchestration: Automatización de despliegues en Docker
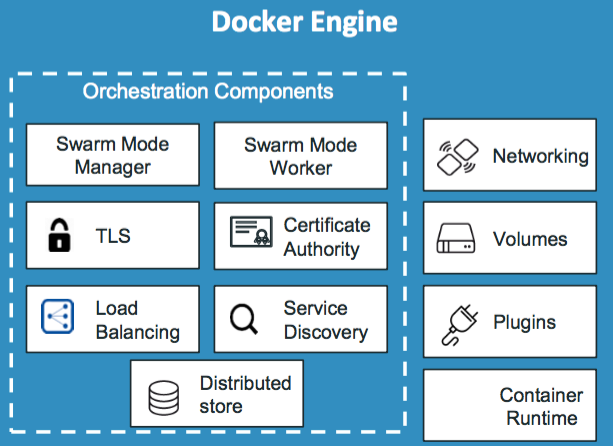 La automatización de despliegues en Docker también se denomina «Docker Orchestration. Hasta ahora hemos visto que con Docker puede ejecutar una sola instancia de la aplicación con un simple comando «Docker run» (ver Práctica con el comando run de Docker). Por ejemplo, para ejecutar una aplicación basada en node js, está en el comando docker run node js. Pero esa es solo una instancia de la aplicación en un host docker. Si aumenta el número de usuarios y esa instancia ya no puede manejar la carga, se implementa una instancia adicional ejecutando el comando docker run varias veces. Es algo que tiene que hacerse manualmente. Se debe vigilar de cerca la carga y el rendimiento de la aplicación e implementar instancias adicionales. Y si un contenedor fallara, hay que ser capaz de detectarlo y ejecutar el comando docker run nuevamente para implementar otra instancia de esa aplicación.
La automatización de despliegues en Docker también se denomina «Docker Orchestration. Hasta ahora hemos visto que con Docker puede ejecutar una sola instancia de la aplicación con un simple comando «Docker run» (ver Práctica con el comando run de Docker). Por ejemplo, para ejecutar una aplicación basada en node js, está en el comando docker run node js. Pero esa es solo una instancia de la aplicación en un host docker. Si aumenta el número de usuarios y esa instancia ya no puede manejar la carga, se implementa una instancia adicional ejecutando el comando docker run varias veces. Es algo que tiene que hacerse manualmente. Se debe vigilar de cerca la carga y el rendimiento de la aplicación e implementar instancias adicionales. Y si un contenedor fallara, hay que ser capaz de detectarlo y ejecutar el comando docker run nuevamente para implementar otra instancia de esa aplicación.
Pero, si el host falla y es inaccesible entonces los contenedores alojados en ese host también se vuelven inaccesibles. Para resolver este problema se necesitaría un ingeniero dedicado que pueda sentarse y monitorear el funcionamiento y el estado de los contenedores y tomar las medidas necesarias para remediar la situación. Pero cuando se tienen implementadas grandes aplicaciones con decenas de miles de contenedores, ese no es un enfoque práctico.
Solución
Por lo tanto, para la automatización de despliegues en Docker se pueden crear scripts para ayudar a abordar estos problemas hasta cierto punto. La orquestación de contenedores es solo una solución para eso. Es una solución que consiste en un conjunto de herramientas y scripts que pueden ayudar a alojar contenedores en un entorno de producción. Por lo general, una solución de orquestación de contenedores consta de múltiples hosts Docker que pueden alojar contenedores de esa manera. Si uno falla, se podría acceder a través de los demás. Una solución de organización de contenedores le permite implementar fácilmente cientos o miles de instancias de una aplicación con un solo comando. Este es un comando utilizado para el enjambre Docker.
Analizaremos el comando en sí un poco. Algunas soluciones de orquestación pueden ayudar a aumentar automáticamente el número de instancias. Cuando los usuarios aumentan y reducir el número de instancias cuando la demanda disminuye. Algunas soluciones incluso pueden ayudar a agregar automáticamente hosts adicionales para admitir la carga del usuario y no solo a agrupar y escalar las soluciones de orquestación de contenedores. También brinda soporte para la creación de redes avanzadas entre los contenedores en diferentes hosts, así como equilibrar la carga de las solicitudes entre los diferentes contenedores. También brindan soporte para compartir almacenamiento entre el host, así como soporte para la gestión de la configuración y la seguridad dentro del clúster.
Aplicaciones para la automatización de despliegues en Docker
Hoy en día, existen múltiples soluciones de orquestación de contenedores. Docker tiene Docker Swarm, Google los Kubernetes o Apache ofrece MESOS. Aunque Docker Swarm es realmente fácil de configurar y de iniciar, carece de algunas de las funciones avanzadas de escalado automático requeridas para aplicaciones complejas de gran producción. Por otro lado, MESOS es bastante difícil de configurar y de iniciar, pero admite muchas características avanzadas. Kubernetes podría decirse que es el más popular de todos, aunque es un poco difícil de configurar y de iniciar, ofrece muchas opciones para personalizar las implementaciones y tiene soporte de muchos proveedores diferentes, ya que es compatible con todos los proveedores de servicios en la nube como GCP, Azure y AWS. Es uno de los proyectos mejor clasificados en github.
Docker Swarm
Docker Swarn tiene muchos conceptos que cubrir y requiere su propio artículo, pero vamos a explicar rápidamente algunos de los detalles básicos para tener una breve idea de lo que es.
Puede combinar varias máquinas Docker en un solo cluster. Se encarga de la automatización de despliegues en Docker distribuyendo sus servicios y sus instancias de aplicación en hosts separados para una alta disponibilidad y para el equilibrio de carga en diferentes sistemas y hardware. Para configurar Docker Swarm primero se debe tener varios hosts con Docker instalados. Luego se debe designar a uno de ellos para que sea el gerente, el maestro o el administrador de Swarm y otros como esclavos o trabajadores. Una vez hecho se ejecuta el comando “docker swarm init” en el administrador de Swarm para que se inicialice el administrador. La respuesta de ese comando proporcionará la orden que se debe ejecutar en los trabajadores para unirse al administrador.
Después de unirse al cluster, los trabajadores (también conocidos como nodos) estarán listos para crear servicios e implementarlos en el clúster de Swarm ejecutando el comando “docker run” específico. Esto crea una nueva instancia de contenedor de la aplicación.
Automatización
Para ejecutar varias instancias de un servidor sería ejecutar el comando “docker run” en cada nodo de trabajo, pero eso no es lo ideal, ya que podría tener que iniciar sesión en cada nodo. Además tendría que configurar el balanceo de carga y monitorizar el estado de cada instancia. Por último, si las instancias fallan, hay que reiniciarlas a mano. Sería una tarea imposible, por lo que la orquestación de Docker Swarm hace todo esto por nosotros.
El componente clave de la orquestación de Swarm es el servicio Docker. Es una o más instancias de una sola aplicación o servicio que se ejecuta en todo el sitio, en todos los nodos en el clúster de Swarmbre. Se podría crear un servicio Docker para ejecutar varias instancias de un servidor web en todos los nodos de trabajo en mi clúster de Swarm. Para esto, se ejecuta el comando “docker service create –replicas=<N> web-server” en el nodo del administrador.
Como se ve, se especifica el nombre de la imagen y se usa la opción “replicas” para especificar el número de instancias del servidor web que deben ejecutarse. Con esto se obtienen instancias del servidor web distribuidas en los diferentes nodos de trabajo. El comando “service” de creación del servicio es similar al comando de ejecución “run”, ya que tiene las mismas opciones, como la variable de entorno -e, -p para publicar puertos, la opción de red para conectar el contenedor a una red, etc.
Kubernetes
Con Docker se puede ejecutar una sola instancia de una aplicación usando comando “docker run”. Con Kubernetes, usando su linea de comando, conocida como control de kube. Ayuda a la automatización de despliegues en Docker ejecutando mil instancias de la misma aplicación con un solo comando (kubectl run –replicas=1000 web-server). Puede ampliarlo hasta dos mil o que lo haga automáticamente. Las instancias y la infraestructura se pueden ampliar y reducir en función de la carga del usuario. Se pueden acumular instancias de la aplicación de forma continua, una a una con un solo comando. Si algo sale mal, puede ayudar a revertir las imágenes con un solo comando. Kubernetes puede ayudar a probar nuevas características de una aplicación actualizando solo un porcentaje de las instancias creando nodos de prueba.
La arquitectura Kubernetes proporciona soporte para muchas redes diferentes y el almacenamiento cubre cualquier estructura de almacenamiento. Admite muchas variedades de mecanismos de autenticación y autorización. Los principales proveedores de servicios en la nube tienen soporte nativo para Kubernetes. Los usuarios de Kubernetes usan Docker para alojar aplicaciones en forma de contenedores. Pero no tiene por qué ser Docker, ya Kubernetes admite como nativos otros como un Rocket o CRI-O.
Arquitectura
La arquitectura de Kubernetes es un clúster compuesto por un conjunto de nodos. Un nodo es una máquina física o virtual en la que se instala un conjunto de herramientas de Kubernetes. El nodo es una máquina de trabajo y es donde Kubernetes lanzará los contenedores. Si el nodo en el que el la aplicación se está ejecutando falla, la aplicación deja de funcionar, por lo que se debe tener más de 1 nodo. Un clúster es un conjunto de nodos agrupados, si un nodo falla, la aplicación es accesible desde otros nodos.
El responsable de administrar este clúster es quien tiene la información sobre el resto de los miembros. Es quien monitoriza los nodos y quien mueve la carga de trabajo. Este es el master. El master es un nodo con los componentes de control de Kubernetes instalados. El master vigila los nodos en el clúster y es responsable de la orquestación real de los contenedores.
Cuando se instala Kubernetes en un sistema, en realidad está instalando los siguientes componentes: un servidor API, un servidor etcd, un servicio kubelet, un motor de tiempo de ejecución de contenedores (Docker), un grupo de controladores y el planificador (Scheduler).
Componentes
El servidor API actúa como interfaz para Kubernetes. La línea de comandos hablan con el servidor API para interactuar con el clúster de componentes. El etcd es un almacén de valores de clave distribuido utilizado por Kubernetes para almacenar todos los datos utilizados para administrar el clúster. Cuando hay múltiples nodos y múltiples maestros en un clúster, etcd almacena toda esa información en todos los nodos en el clúster de manera distribuida. etcd es responsable de implementar registros dentro del clúster para garantizar que no haya conflictos entre los maestros.
El planificador es responsable de distribuir el trabajo de los contenedores en múltiples nodos, busca contenedores recién creados y los asigna a los nodos. Los controladores son el cerebro detrás de la orquestación, son responsables de responder cuando los contenedores de nodos caen. Los controladores toman decisiones para abrir nuevos contenedores en esos casos. El motor de tiempo de ejecución (runtime container) es el software que se utiliza para ejecutar contenedores, que, en nuestro en caso, es Docker. Finalmente kubelet es el agente que se ejecuta en cada nodo del clúster y es el responsable de asegurarse de que los contenedores se estén ejecutando en las nodos tal como se esperaba.
La utilidad de línea de comando conocida como kube, ya que también es una herramienta de control. kube se usa para implementar y administrar aplicaciones en un clúster de Kubernetes, para obtener información relacionada con el clúster, para obtener el estado de los nodos en el clúster y muchas otras cosas.
El comando “kubectl run <aplicacion>” se usa para implementar una aplicación en el clúster, el comando “kubectl cluster-info” se usa para ver información sobre el clúster y el comando “kubectl get nodes” muestra los nodos que forman parte del clúster.
Hay más información en la web de Kubernetes: https://kubernetes.io/es/


