
Aprendizaje supervisado
Una manera fácil de empezar a entender el concepto de aprendizaje supervisado es observando directamente a las palabras que lo componen: Supervisado significa observar y dirigir la ejecución de una tarea, proyecto o actividad. Obviamente, no nos referimos a supervisar una persona, supervisamos un modelo de machine learning que podría ser capaz de producir regiones de clasificación.
Pero, ¿cómo supervisamos un modelo de machine learning? Lo hacemos «educando» el modelo, es decir, cargamos el modelo con conocimiento para que pueda predecir las instancias futuras. Y esto nos lleva a otra pregunta, «¿Cómo se educa exactamente un modelo?» La educación del modelo se raliza entrenándolo con algunos datos de un conjunto de datos con etiquetas. Así, es importante tener en cuenta que los datos están etiquetados.
Unos datos etiquetados se muestran como un conjunto de filas y columnas donde cada fila son los datos de una sola observación de un objeto de estudio y la columnas son características observadas. Por ejemplo, para una célula podemos tener características como su espesor, tamaño de la celda, adhesión marginal, etc..
Los datos pueden ser de dos clases: numérica (los más frecuentes) o categórica (usados como clasificadores)
Para este aprendizaje existen dos
técnicas:
- La clasificación es el proceso de predecir una categoría o etiqueta de clase discreta.
- La regresión es el proceso de predicción de un valor continuo en contraposición a la predicción un valor categórico en Clasificación.
Aprendizaje no supervisado
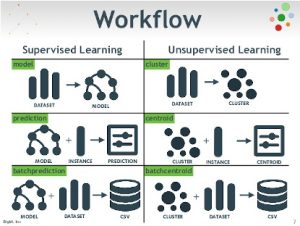
En el aprendizaje no supervisado dejamos que el modelo trabaje por su cuenta para descubrir información que puede que no ser visible para el ojo humano. Esto significa que el algoritmo no supervisado entrena con el conjunto de datos, y extrae conclusiones sobre datos sin etiquetar. En términos generales, tiene algoritmos más difíciles que el aprendizaje supervisado, ya que sabemos poco a nada sobre los datos o los resultados que se esperan.
Las técnicas más utilizadas son:
- La reducción de dimensiones y/o la selección de características desempeñan un gran papel reduciendo las características haciendo que la clasificación sea más fácil.
- El análisis de carritos de la compra es una técnica de modelado basada en la teoría de que si se compra un cierto grupo de artículos, es más probable que compres otro grupo de artículos.
- La estimación de densidad es un concepto muy simple que se utiliza principalmente para explorar los datos y encontrar alguna estructura interna.
- El agrupamiento o clustering es considerado como una de las técnicas más populares en machine learning no supervisado utilizada para agrupar los puntos de datos u objetos similares de algún modo. El análisis de clústeres tiene muchas aplicaciones en diferentes dominios, ya sea pare que un banco quiera segmentar a sus clientes en función de determinadas características, o de ayudar a un individuo a organizar y agrupar sus tipos de música favoritos
Por lo tanto, la mayor diferencia entre el Aprendizaje supervisado y no supervisado es que el aprendizaje supervisado se ocupa de los datos etiquetados mientras que el aprendizaje no supervisado se ocupa de datos no etiquetados. En el aprendizaje supervisado, tenemos algoritmos de machine learning para Clasificación y Regresión.
Ir al artículo anterior de la serie: Python para Machine Learning. Paquetes más usados.
Ir al artículo siguiente de la serie: Introducción al Modelo de Regresión

